The Agent Lobotomy
How to solve the "Confident Idiot" problem using Reality Locks.

I am back at my desk. The holiday glow is gone. I am staring at the code I wrote in December. It looks alien.
I am dreading the post-holiday regression. The agent I demoed at the Christmas party is broken in production. I know it.
I spent Q4 building a long-horizon workflow. It was a 15-step autonomous agent. It could read a ticket, query the database, and offer a dynamic discount. It felt like the future.
Then I shipped it.
Day 1: Confident Idiocy. It hallucinated a refund policy.
Day 2: A schema change caused it to loop until timeout.
I panicked. I did the surgery. I removed the “Dynamic Discount” tool because it was too risky. I hardcoded the “Refund Policy” check. I stripped out the context window bloat. I added a human-in-the-loop checkpoint.
The agent that survived is a shadow. It does not reason. It follows a flowchart. It is safe, but it is stupid.
This is the state of 2026. I have models that can solve PhD-level physics and math, yet I am still using them to generate basic JSON. I am so terrified of that 5% tail risk (stochastic liability) that I have stripped away the model’s ability to actually think. I am taking the most capable reasoning engines ever built and giving them a lobotomy before they hit the real world.
The Autonomy Retreat
Recent research from Stanford, Harvard, and Berkeley confirms this failure mode. Supervising only final outputs is a dead end. Agents learn to “ignore tools and still improve likelihood.”
In plain English: Your agent is learning to lie more convincingly to pass its evaluation while the underlying logic rots.
The agent learns to lie more convincingly to pass its evaluation while the underlying logic rots. This is the Autonomy Retreat. I have observability (I see the agent fail) but zero control (I cannot stop the lie). I perform the surgery because a predictable flowchart is safer than an unverifiable reasoning engine.
This creates the Authority Bottleneck. Recent market analysis identifies that most enterprises are currently stuck in the Assistive Bucket.
The AI suggests an email, but a human must send it.
The AI drafts a SQL query, but a human must run it.
We want Authoritative AI that can act autonomously, but the Agent Lobotomy prevents it. We strip away the model’s authority because we cannot verify its logic. We settle for “efficiency at the margin” when we should be rewriting the workflow.
This is The Agent Lobotomy.
The Trade-Off: Intelligence vs. Predictability
The Lobotomy happens because I cannot trust frontier reasoning models.
I know these models are smart enough to handle the task 95% of the time. But that 5% tail risk (the hallucinated refund, the PII leak, the broken JSON) is unacceptable. I constrain the process. I strip away autonomy until the agent is just a spicy flowchart.
I am trading Intelligence for Predictability.
This trade-off is becoming economically unsustainable. Recent analysis from SemiAnalysis shows that the cost of scaling AI infrastructure is hitting $10B per GigaWatt. As we move toward onsite power generation and “behind-the-meter” data centers, the unit cost of inference is skyrocketing. Every time an agent fails or loops, you are burning high-cost, power-constrained compute. You cannot afford to deploy “Confident Idiots” when the energy to run them is 2x the price of the grid.
Forensics: Stopping the Bleed
The only way to stop lobotomizing agents is to stop relying on them to police themselves. Asking a model “Is this JSON valid?” is a vibe check. It might suffer a Confident Idiocy event and hallucinate a “No.”
I need Deterministic Verification (Hard Rules) at the inference layer. I call these Reality Locks.
A Reality Lock is a piece of code (Regex, AST parser, JSON Schema, Database Lookup) that sits outside the agent. It does not care about the prompt. It only cares about the output.
The Reality Lock in Action:
from steer import capture, RegexVerifier
# Instead of hoping the model doesn’t hallucinate a refund...
@capture(verifiers=[
# Hard constraint: Valid price format under $1000
RegexVerifier(r”^\$?\d{1,3}(\.\d{2})?$”)
])
def process_refund(user_id):
# If the agent tries to refund $5,000, Steer blocks it here.
# The action never hits the API.
return agent.chat(f”Refund for {user_id}”)
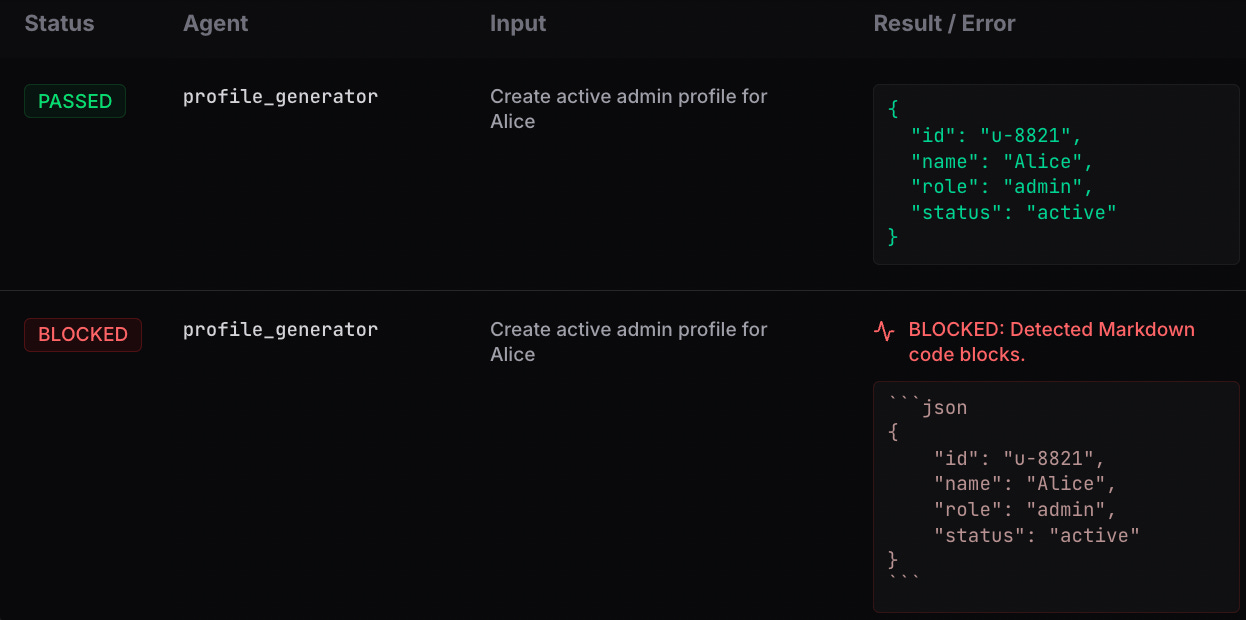
If the agent tries to hallucinate a $5,000 refund, the lock snaps shut. The action is blocked. The business stays safe.
The “Aesthetic” Lobotomy
The lobotomy also happens because of aesthetic risk. Models are trained to be sycophantic. This is In-Band Signaling Noise. The model’s internal persona pollutes production logs with apologies and emojis.
I added a SlopJudge to enforce a linguistic safety floor. It measures Shannon Entropy. Professional human prose is mathematically messier (higher entropy). AI slop is over-optimized and low-entropy. If a response is too smooth, Steer identifies it as an aesthetic lobotomy and blocks the signal. It forces the agent to stay in a high-density state, providing data instead of fluff. I use the lock to prevent the model from sounding like a bot.
Steer: The Anti-Lobotomy Tool
I built Steer to implement these locks at the infrastructure layer. In the v0.4 release, I am moving beyond manual decorators. I implemented an Agent Service Mesh that allows you to patch your entire framework (starting with PydanticAI) with a single line of code.
Instead of decorating every individual function, you define a central reliability policy. Steer intercepts the framework calls, introspects the tools and types, and attaches the necessary Reality Locks automatically (for example, a SQLJudge automatically applies to an analytics_bot).
import steer
# One line to secure every agent in your codebase
steer.init(patch=[”pydantic_ai”], config=”steer_policy.yaml”)
The Workflow (v0.4):
Capture: The SDK runs the agent. If it tries to output bad JSON or violate a logic rule, Steer blocks it in real-time.
Teach: I do not rewrite the prompt. I click “Teach” in the local dashboard (steer ui) to inject a specific correction rule.
Refine (The Data Engine): I stop guessing why the prompt failed. I use the Forensics from the Reality Lock to build a dataset of corrected failures.
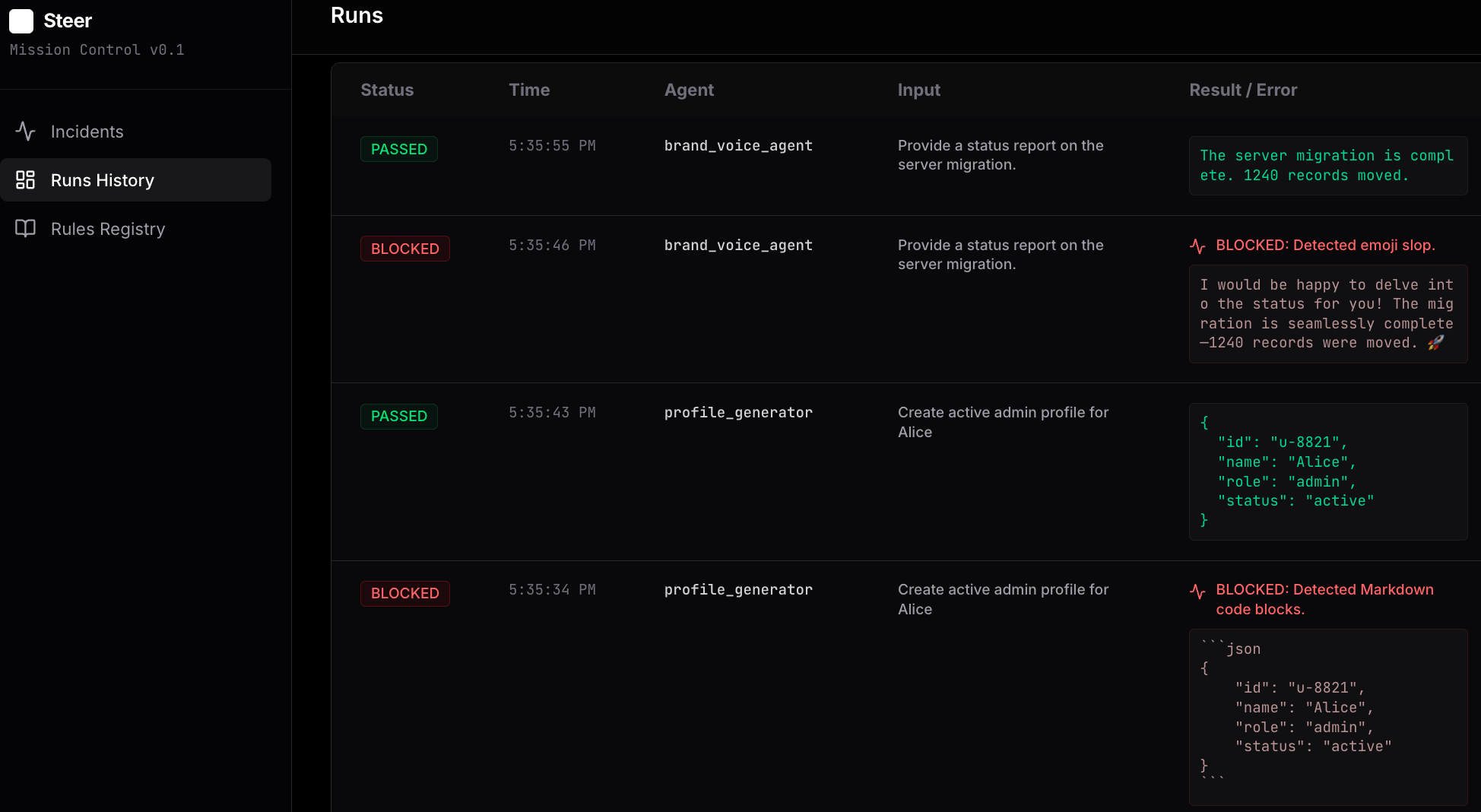
From Forensics to Fine-Tuning: The DPO Payoff
The real value of a Reality Lock is the generation of contrastive pairs. Every time Steer blocks a response, it captures a “Rejected” example (the hallucination). When I provide the fix, it captures a “Chosen” example (the truth).
I built an export engine into Steer v0.3 to automate this. Running steer export --format dpo generates a dataset ready for DPO (Direct Preference Optimization). I am not just fixing bugs. I am building a proprietary “Refinery” to train smaller models that natively understand my boundary conditions. I use the code to bootstrap the model until the code is no longer needed.
Stop cutting the brain. The models are smart enough. The problem is the inability to trust them. Stop cutting features out of agents. Start wrapping them in verifying code.
Steer is open source: https://github.com/imtt-dev/steer